 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Asset eXchange: Path to Ubiquitous Deep Learning Deployment
Sep 04, 2019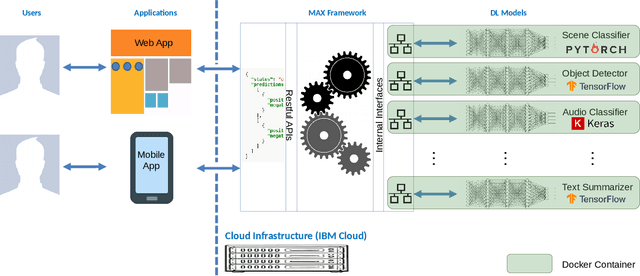

A recent trend observed in traditionally challenging fields such as computer vision and natural language processing has been the significant performance gains shown by deep learning (DL). In many different research fields, DL models have been evolving rapidly and become ubiquitous. Despite researchers' excitement, unfortunately, most software developers are not DL experts and oftentimes have a difficult time following the booming DL research outputs. As a result, it usually takes a significant amount of time for the latest superior DL models to prevail in industry. This issue is further exacerbated by the common use of sundry incompatible DL programming frameworks, such as Tensorflow, PyTorch, Theano, etc. To address this issue, we propose a system, called Model Asset Exchange (MAX), that avails developers of easy access to state-of-the-art DL models. Regardless of the underlying DL programming frameworks, it provides an open source Python library (called the MAX framework) that wraps DL models and unifies programming interfaces with our standardized RESTful APIs. These RESTful APIs enable developers to exploit the wrapped DL models for inference tasks without the need to fully understand different DL programming frameworks. Using MAX, we have wrapped and open-sourced more than 30 state-of-the-art DL models from various research fields, including computer vision, natural language processing and signal processing, etc. In the end, we selectively demonstrate two web applications that are built on top of MAX, as well as the process of adding a DL model to MAX.
* 4 pages, 3 figures. Demo paper
Video based Contextual Question Answering
Apr 19, 2018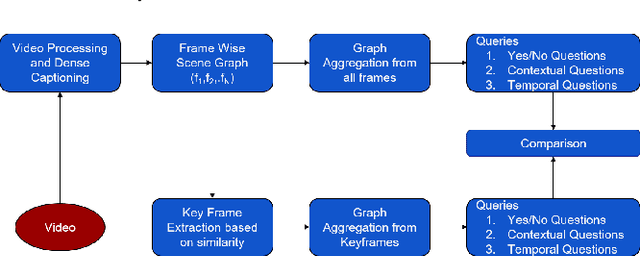
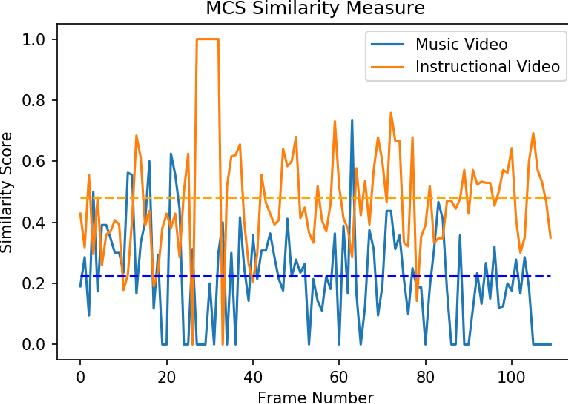
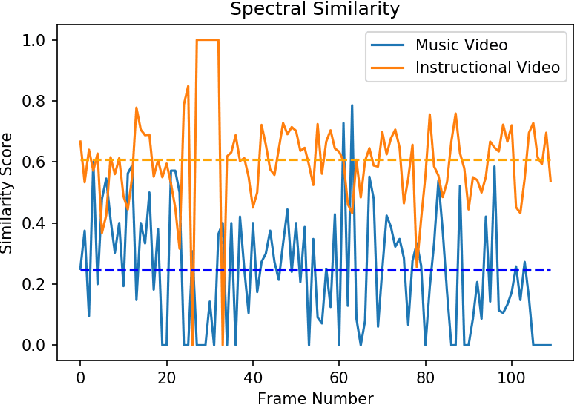
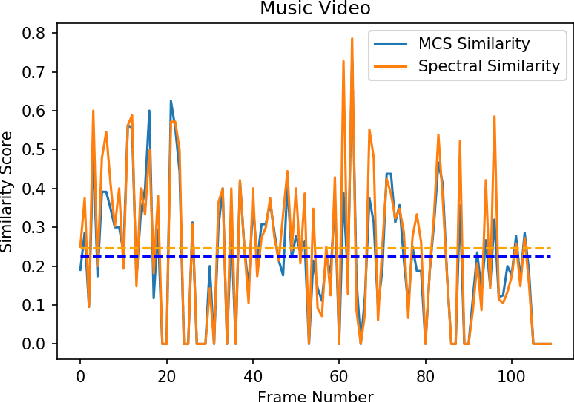
The primary aim of this project is to build a contextual Question-Answering model for videos. The current methodologies provide a robust model for image based Question-Answering, but we are aim to generalize this approach to be videos. We propose a graphical representation of video which is able to handle several types of queries across the whole video. For example, if a frame has an image of a man and a cat sitting, it should be able to handle queries like, where is the cat sitting with respect to the man? or ,what is the man holding in his hand?. It should be able to answer queries relating to temporal relationships also.
Vision Based Dynamic Offside Line Marker for Soccer Games
Apr 17, 2018

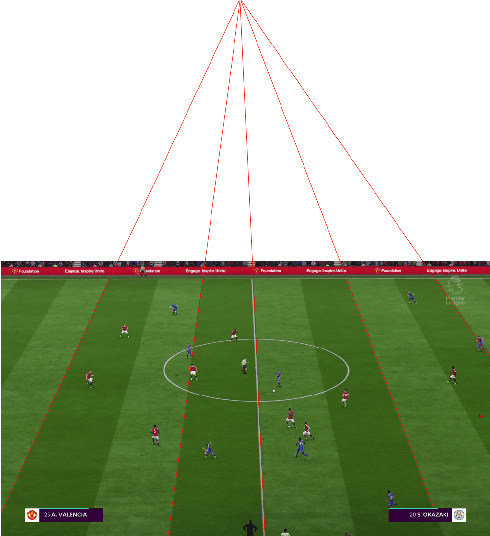
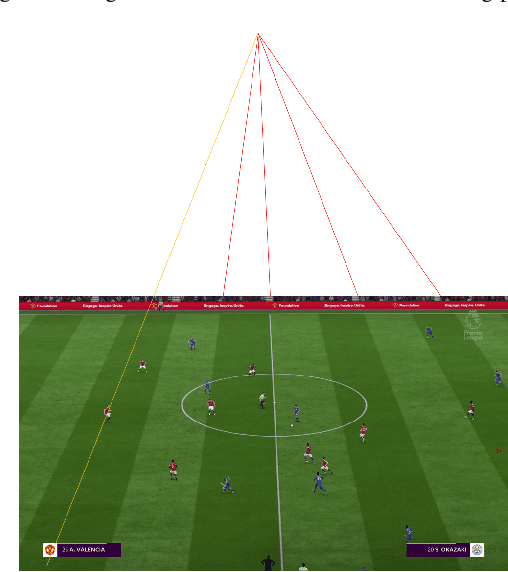
Offside detection in soccer has emerged as one of the most important decisions with an average of 50 offside decisions every game. False detections and rash calls adversely affect game conditions and in many cases drastically change the outcome of the game. The human eye has finite precision and can only discern a limited amount of detail in a given instance. Current offside decisions are made manually by sideline referees and tend to remain controversial in many games. This calls for automated offside detection techniques in order to assist accurate refereeing. In this work, we have explicitly used computer vision and image processing techniques like Hough transform, color similarity (quantization), graph connected components, and vanishing point ideas to identify the probable offside regions. Keywords: Hough transform, connected components, KLT tracking, color similarity.